UPD 25.02.2019 > Проблема решена. Запись неактуальна.
Так уж получилось, что пока Яндекс разрабатывает сложные нейронные сети и искусственный интеллект, который пишет музыку, рисует и занимается всякими другими делами, я провожу простые многочисленные эксперименты по автоматическому сбору семантики из сервиса Я.Директ. И обнаружил очень неприятный баг системы, который может проявить себя в любое время, а вы даже и не поймете.
В настоящий момент практически все инструменты по сбору статистики для рунета завязаны на данных Яндекса. Но что если происходит глюк системы? Получается какой бы инструмент вы не выбрали, то все равно можете столкнуться с этой проблемой, а именно ошибочной частоткой.
Так о чем я?
Пример 1. Стенки.
Запрос "Стенки", регион Москва и Московская область (код 1), период 30 дней. Обычная конфигурация для парсинга по коммерческой высокочастотке.
Я собрал ~4 000 слов. И собрал базовую и точную частоту ("!W"). Далее сортирую. И вот что вижу. Точная частота просто пляшет и сервис выдает какие-то нереальные цифры.
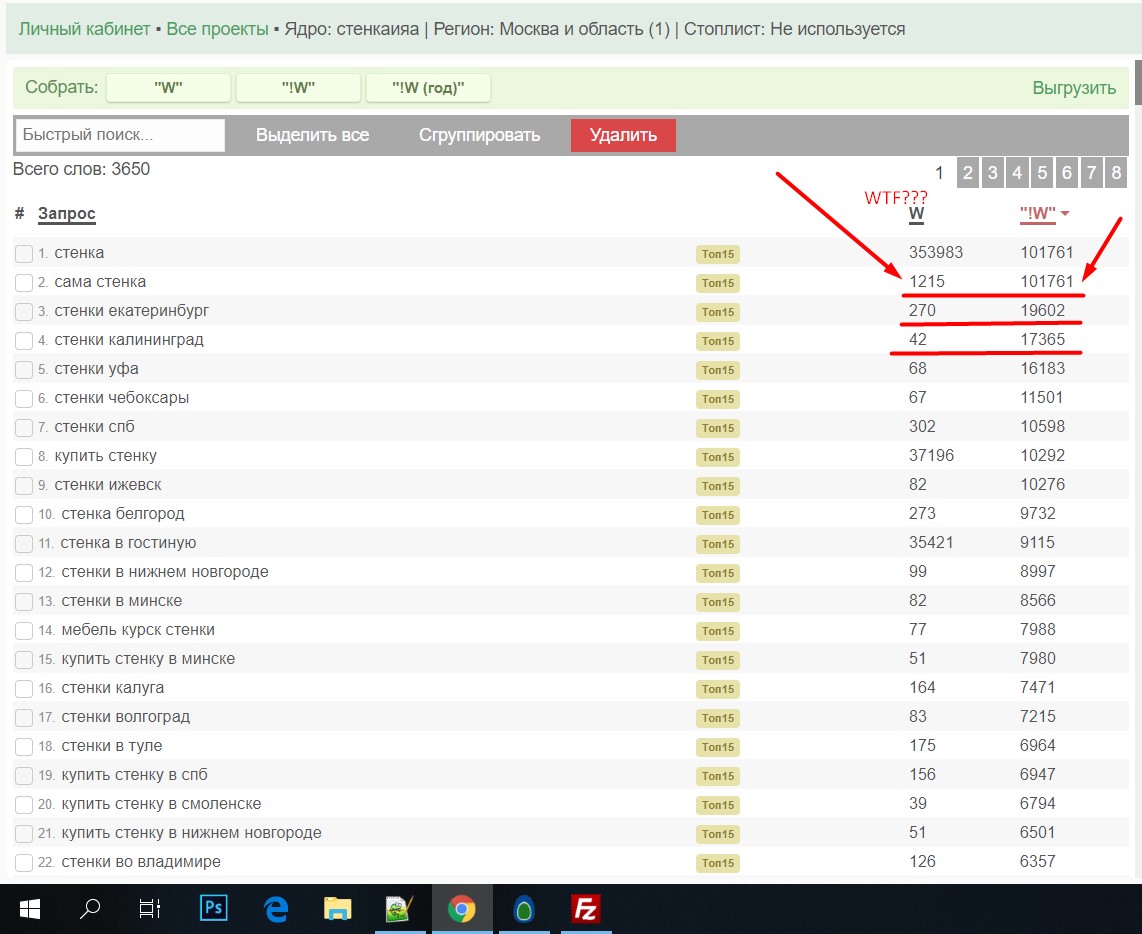
Изначально я подумал, что виноват сервис. Ну баг какой-то, нужно исправить. Но после некоторого анализа выяснилось, что здесь нет программной ошибки, а ошибка скрыта куда глубже.
Запускаем популярную прогу Кей Коллектор. Настройки те же самые (Москва и МО, период 30 дней). Проверяем, как обстоят дела у этих ребят. И знали ли они об этом волшебном глюке, может нашли даже причину? Все же работает целый отдел прогеров.
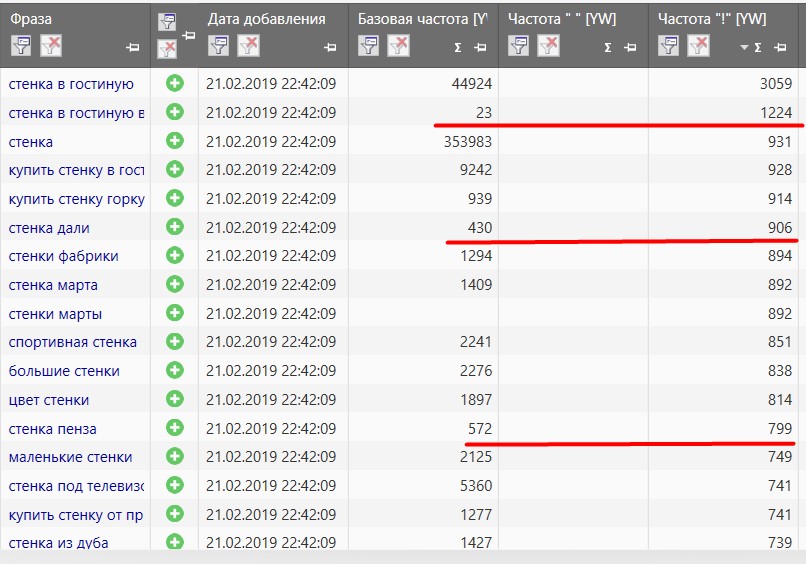
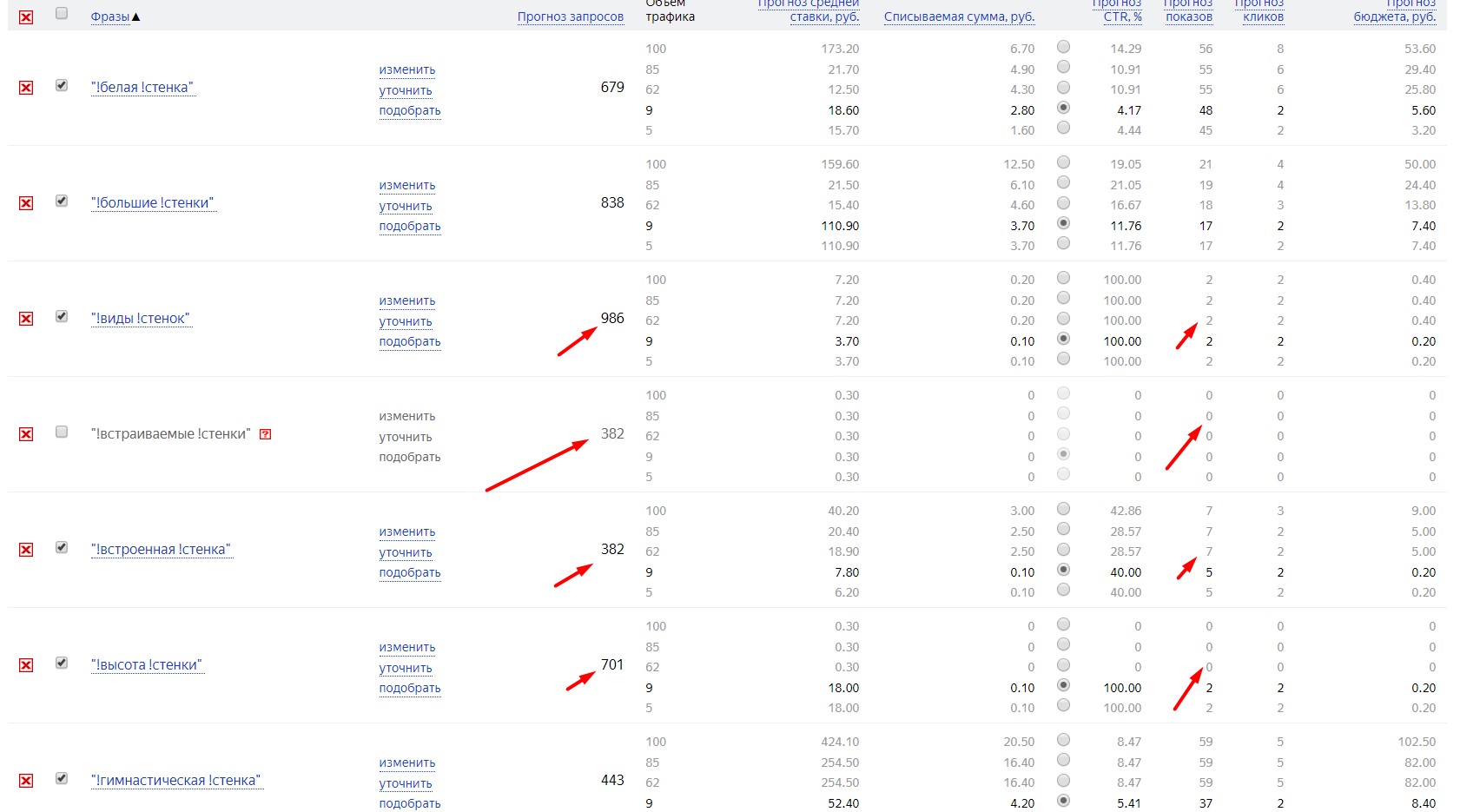
Опа! А вы думали что-то изменится? Да, здесь представлены другие запросы,но я даже не стал дальше собирать, итак все понятно. Посмотрите на эти цифры. Опасность всего этого сбора в том, что ВСЯ ПАЧКА запросов имеет неправильную частоту. Если с запросами, где точная частота выше базовой все понятно, то что с остальными? Посмотрите сами!
Запрос "Большие стенки" имеет базу 2276, а точную 838. Думаете это реальная цифра? Проверяем в yandex.wordstat.
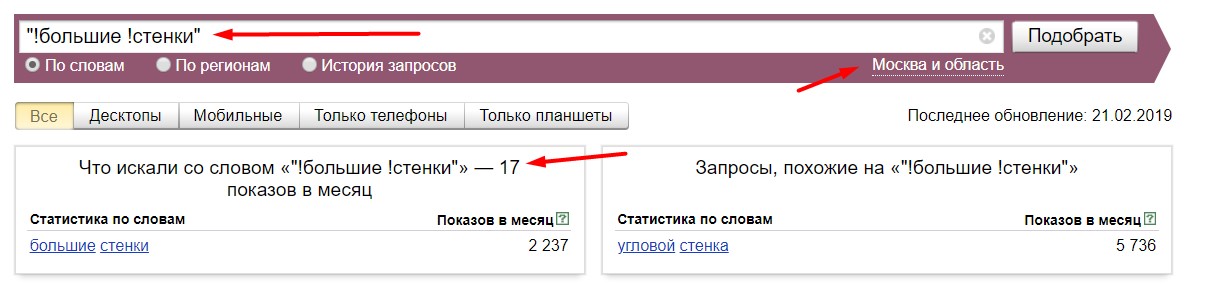
А вот хрен! Хотя на первый взгляд может показаться все логично! А теперь представьте сколько полезных фраз вы могли удалить, а всякого говна оставить при разных автоматических или ручных чистках? Хорошо, если опытный сеошник проверяет сразу множество параметров. Или вы думаете, что частота "W" покажет другие цифры? И тут все так же. Глюк на глюке.
Давайте проверим еще запрос.
"Стенка из дуба". База - 1427, точная по КК - 739. Смотрим, что на самом деле точная частота 9, блеать!
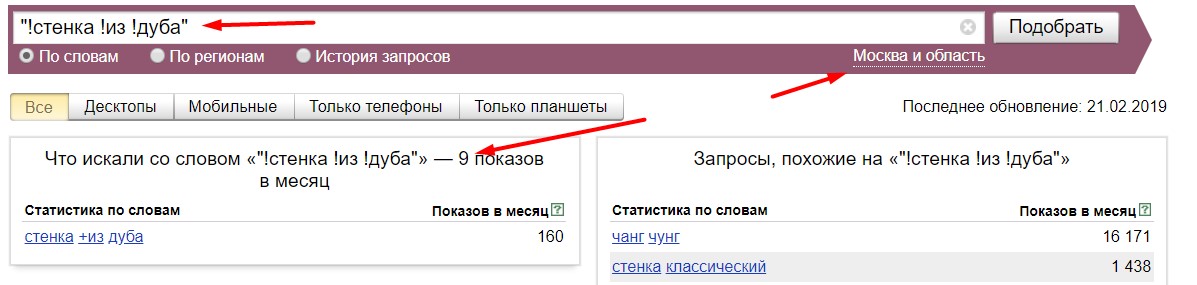
Вы так можете пробить каждый запрос и убедитесь в этом сами. Но давайте копнем еще глубже и узнаем откуда ноги растут! Зайдем на официальный сайт Яндекса, откроем инструмент "Прогноз бюджета" (источник данных) и вобьем наши стенки. Настройки такие же (Москва и мо, период 30 дней). Что получим, как думаете?
Вот так! Думаете, что здесь представлены реальные данные по запросам? Можем пробить по нашему любимому wordstat.
Берем запрос "Встроенная стенка", прогноз показывает, что точная частота 382, хотя прогноз показов 0 (чувствуете как внутри вас что-то напрягается? Да-да, где-то наебка)
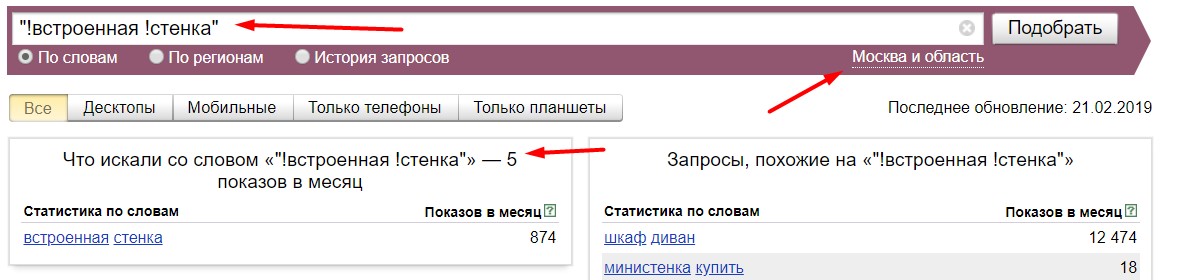
Теперь все встало на свои места и мы знаем, что с данными играется сам Яндекс. Настоящая частота этого запроса = 5.
Пример 2. Шкафы купе.
Регион Москва и МО. Период 30 дней.
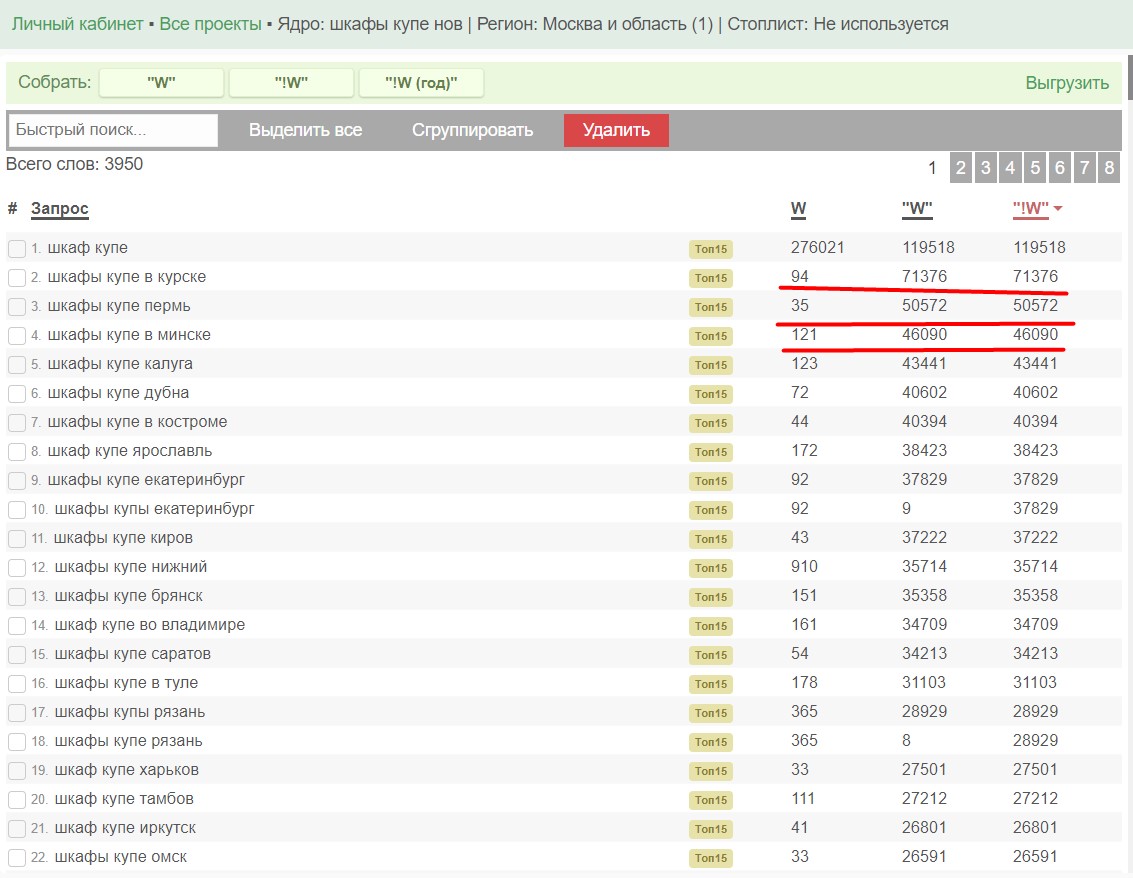
Как видим, что и "!W", и "W" отдает неправильные данные. Напомню, что такие данные подкидывает сам Яндекс. В этом ядре практически вся статистика теперь перепутана, даже те, которые покажутся правильными - все вранье!
Пример 3. Пряжа Ализе пуффи.
Регион Россия. Период 30 дней. Практически вся статистика перепутана.
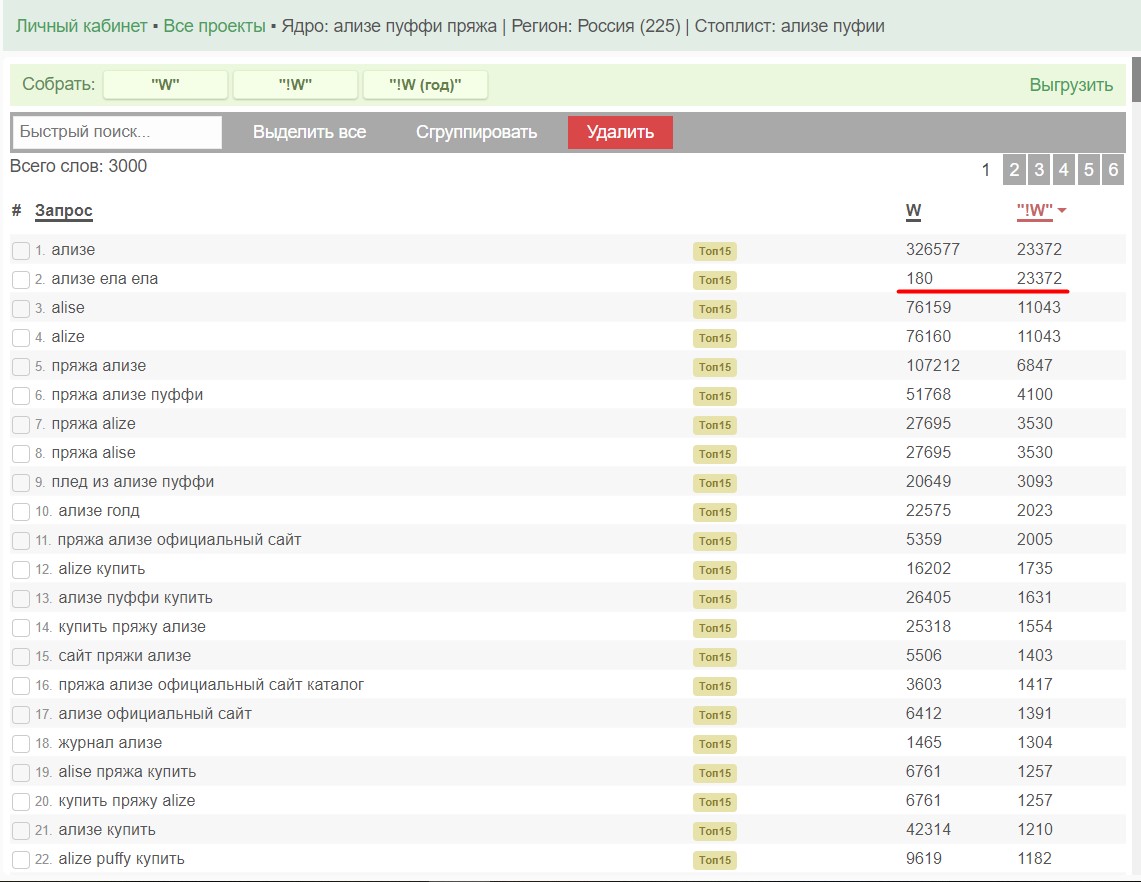
И таких примеров множество! Это полнейшая дичь.
Выводы
- Теперь не ясно где какие данные приходят, будь то продвинутый сервис или ваш любимый Кей Коллектор.
- Я провел различные эксперименты и не смог определить в каких ситуациях появляется этот баг.
- Не во всех запросах творится такой бардак.
- Есть предположение, что у Яндекса что-то перепутано в связи с февралем (28 дней, а не 30), т.к. я проверил более старые ядра другого месяца и в них все нормально.
- Я написал в поддержку Яндекса. Там как обычно ничего не понимают и отвечают раз в трое суток. Никакой информации.
- Я написал в поддержку Кей Коллектора. Вдруг ребята трудятся над решением этой проблемы. Но не тут то было, они и сами не знают что делать. Ответ последовал такой: "Здравствуйте.Такая особенность Директа действительно иногда проявляется: в пакетном режиме он может выдавать нереальные значения частот для некоторых фраз. Контролировать можно, сравнивая колонку частот с колонкой "Показы YD": если расхождение слишком большое, то есть вероятность, что данные от отдал неправильные." А что делать то в итоге? Не понятно.
- Я не хочу никого расстраивать, но на колонку "Показы YD" не стоит сильно рассчитывать, т.к. она иногда сама отдает нереальные значения. После некоторых экспериментов я выявил, что данные в "прогнозе запросов" и "прогнозе показов" могут разниться до 1000 и более запросов. Это же полный фальш!
- В инете об этой теме информации практически нет. Я решил предупредить читателей об этой опасности. Будьте внимательны, собирая частотность, перепроверяйте запросы выборочно ручками.
- UPD > На данный момент, появилось одно решение для сбора ПРАВИЛЬНОЙ частоты, но оно потребует некоторых экспериментов. Один минус - по времени собирается дольше.
Я очень надеюсь, что это лишь временный баг системы Яндекс и они вскоре все исправят.
UPD> Нашел тему в группе ВК Кей Коллектора от 16 января 2018 года , вот ссылка, где поддержка рассказывает про проблему разных статистических данных. Увы, да ах. Этот баг, оказывается, уже живет целый год и Яндекс ничего с этим не делает :(






Курский бомж http://kurskhomeless.ru/