Привет всем!
Давно ничего не писал в блог, да и времени особо не было. Много всякой работы. В ближайшее время хочу написать пост о том, что было заработано, мысли, дальнейшие планы, но пока поговорим о wordkeeper. (https://word-keeper.ru)
Некоторые уже слышали про этот инструмент и активно используют его в своих проектах. Он абсолютно бесплатный.
За время работы сервиса (с 21.08.2018 года):
- Скачено из yandex.wordstat ~ 3.000.000 запросов
- Создано ~ 1000 проектов
- Зарегано 176 человек.
Долгое время сервис не обновлялся, но сейчас я решил исправить этот недочет. Т.к. сам им пользуюсь. Это большое обновление, в которое вложено много сил и времени. Конечно, остались еще баги, но со временем все приведу в порядок. Трудно говорить о какой-то стабильности в работе, когда приходится работать с Яндексом и его антибот системой. Если уж даже у кейколлектора забит весь тех раздел проблемами, то о чем тут говорить :)
Также я постарался учесть множество пожеланий людей, которые писали мне на почту или в чат сервиса.
Итак, обновление.
1. Полностью изменил дизайн. Уменьшил шапку у сайта.
2. Увеличил рабочую площадь в проекте. Теперь окно бьется на 2 части. И во второй части появились вкладки с различным функционалом.
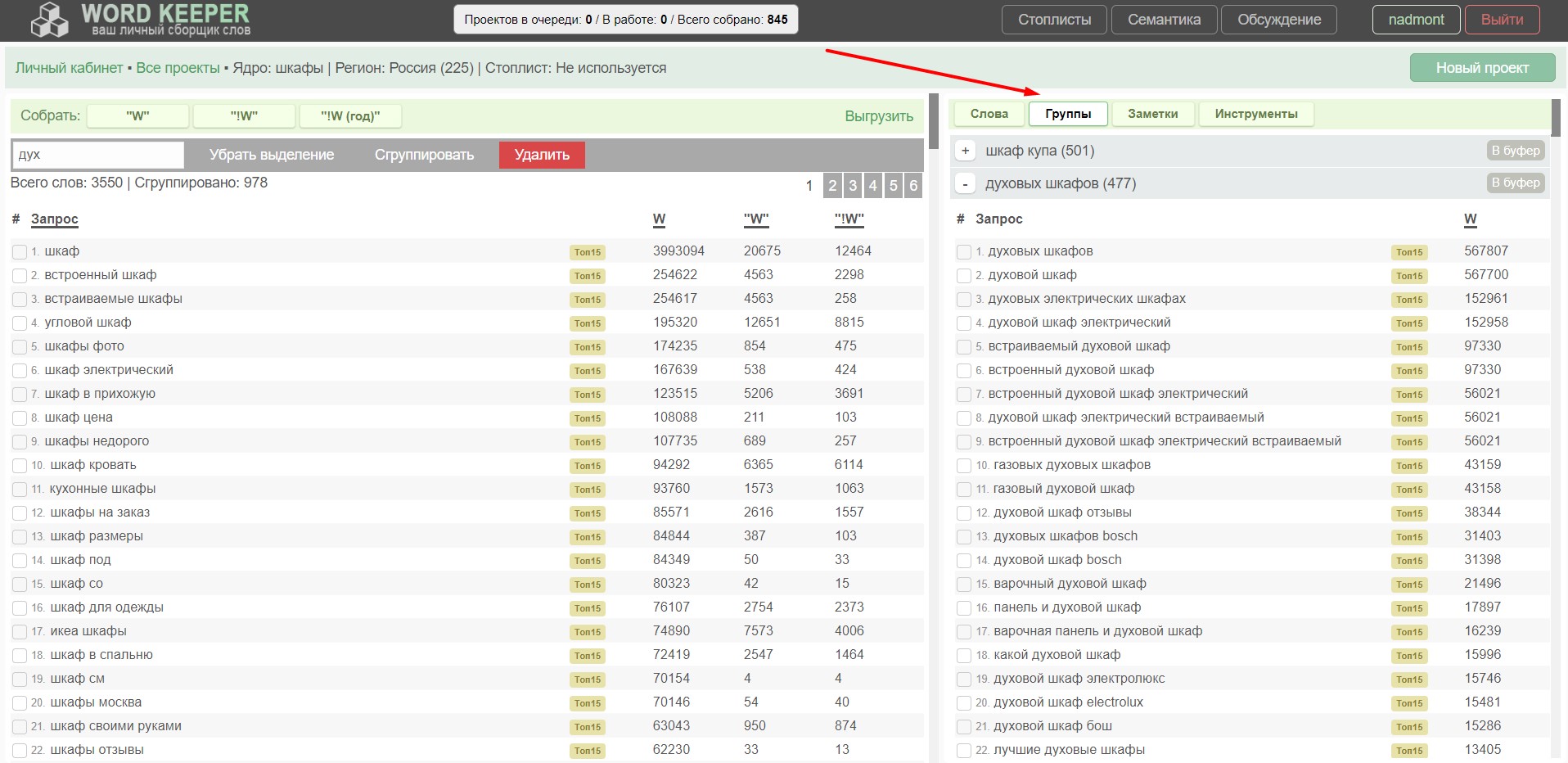
Вкладки:
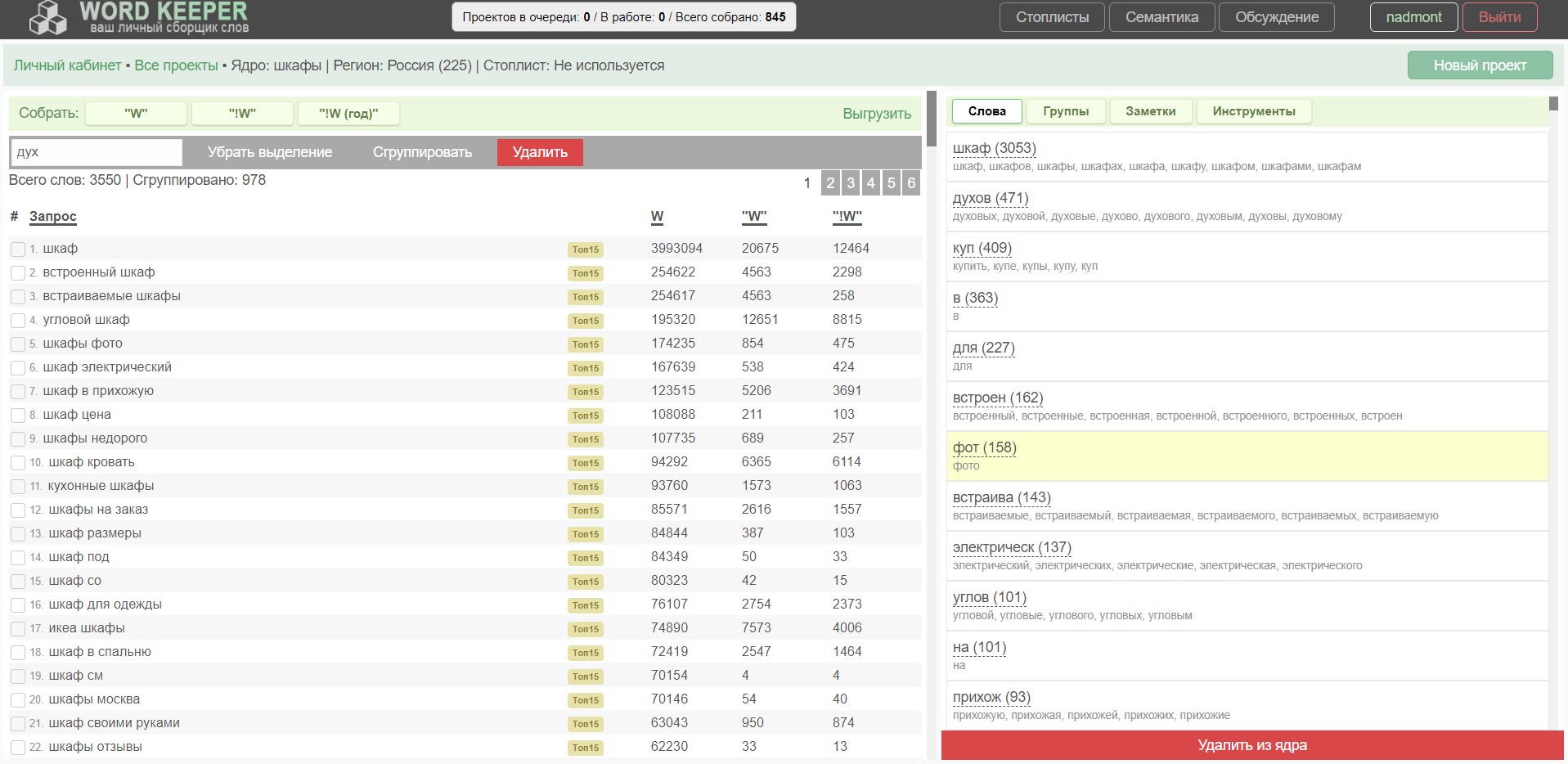
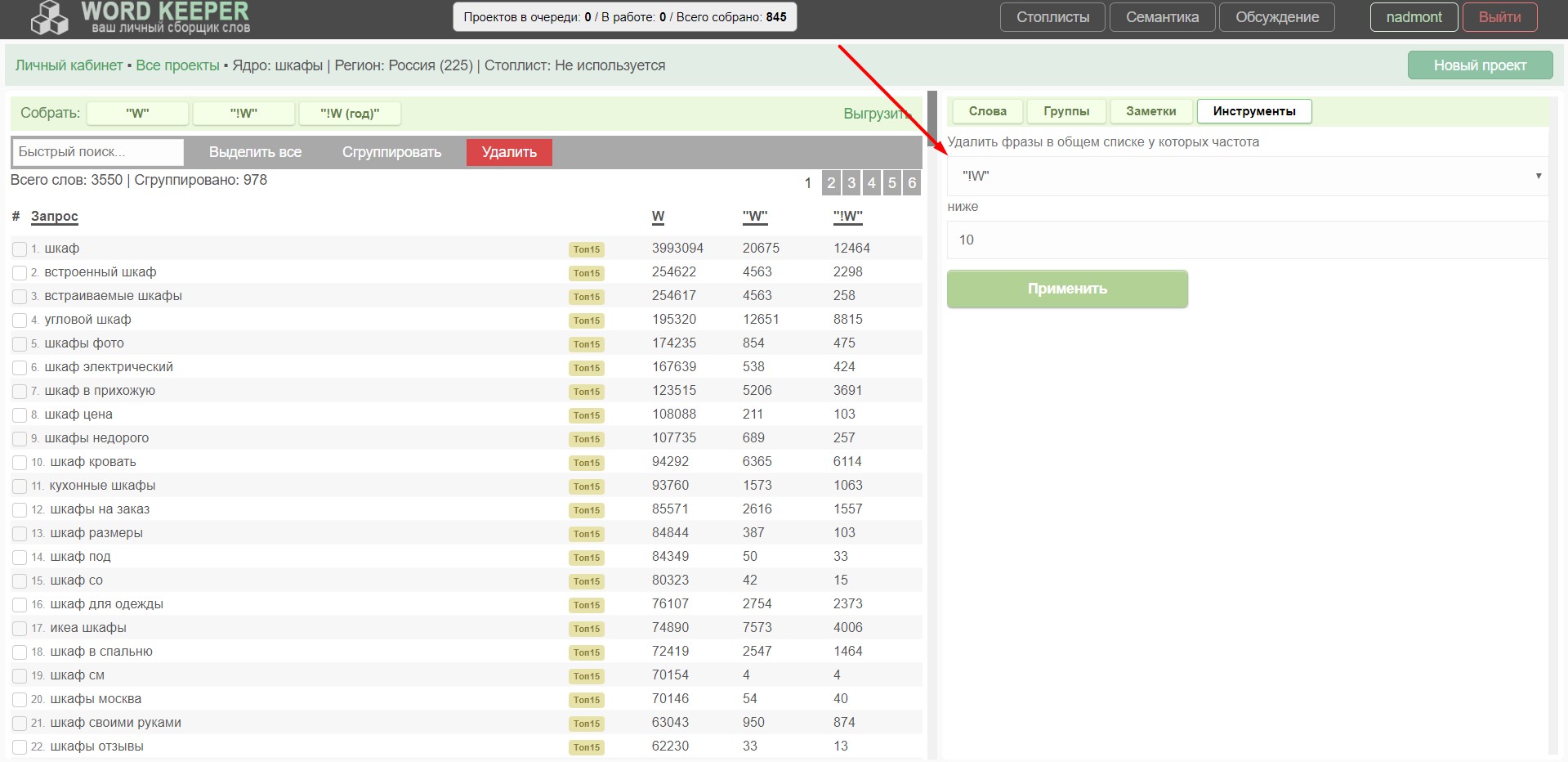
- Слова. Здесь всем привычный стеммер. Показывает количество слов в проекте. Кстати, эти слова можно выделить и автоматически удалить из ядра. Повышает скорость чистки семантики.
- Группы. Это раздел тоже изменился: появился ТОП15, поработал над дизайном, функциональная кнопка "В буфер" для копирования запросов из группы. При нажатии на колонку частоты, она сменится на другую (если такова была собрана).
Вкладка группы - Заметки. Небольшая область для ваших заметок или ТЗ. Используйте как хотите, или не используйте :)
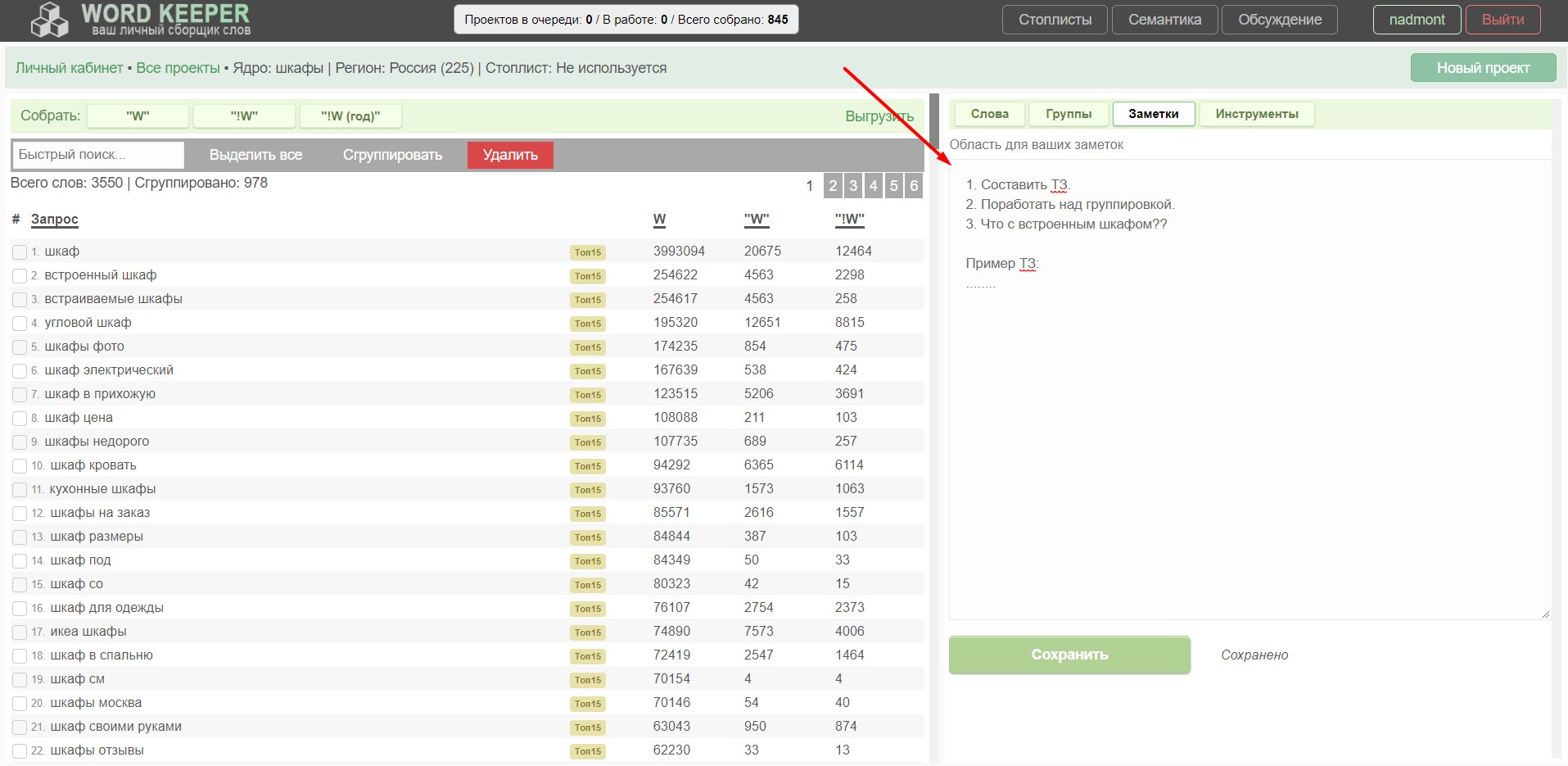
Поле для вашей фантазии :) - Инструменты. Здесь будет сборник инструментов для работы с ядром. Пока реализован только 1 инструмент: чистка по частотке. Можно быстро отсеять низкочастотные фразы из ядра. Секундное дело!
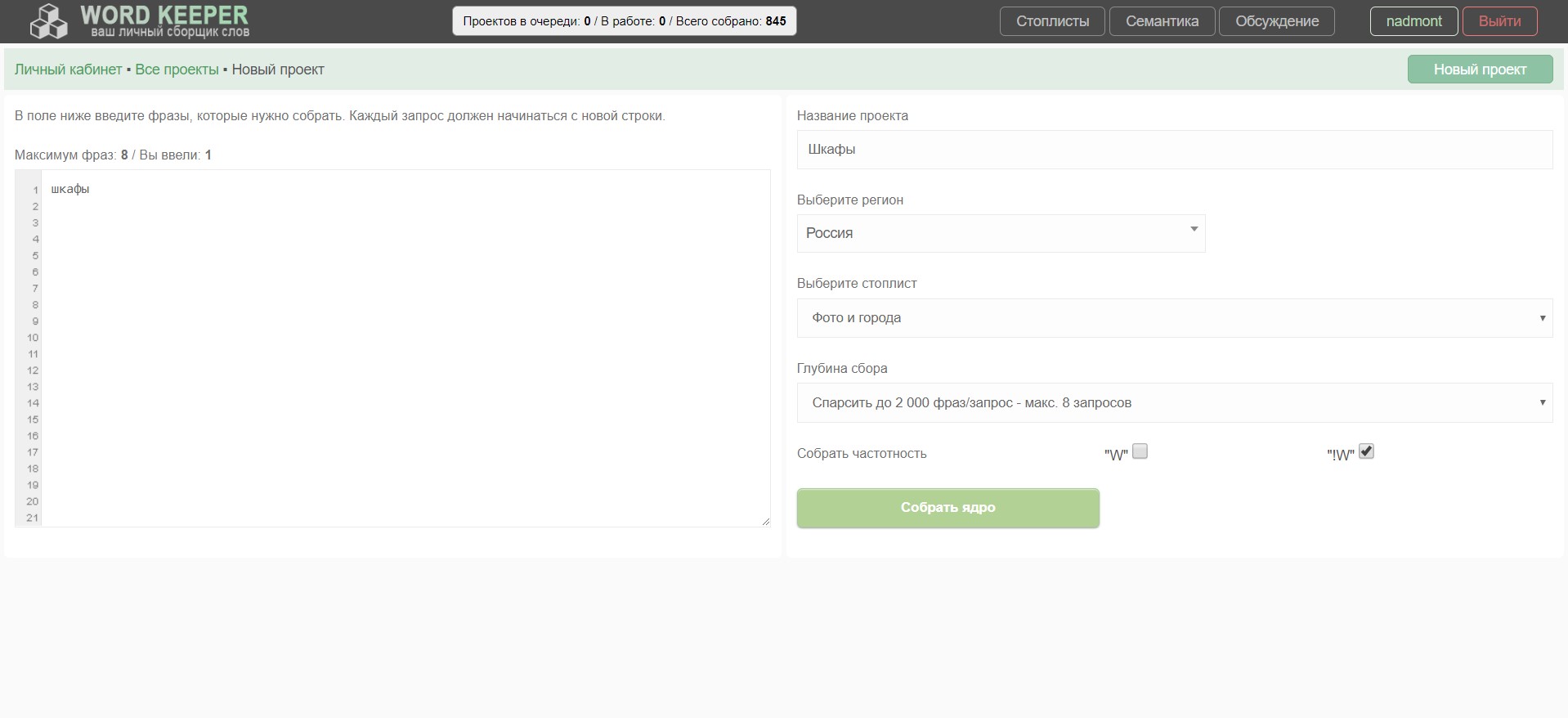
3. Полностью переработан функционал создания нового проекта. Сменил дизайн, теперь можно выбрать стоплист, появилась глубина сбора, и то чего многие ждали: сбор сразу нужных частотностей ("W", "!W").
Глубина сбора сейчас такая:
- Макс 80 фраз, каждая по 200 слов. Для быстрого парсинга и любителей низкочастоток.
- Макс 40 фраз, каждая по 400 слов.
- Макс 16 фраз, каждая по 1000 слов.
- Макс 8 фраз , каждая по 2000 слов.
- Макс 4 фразы, каждая по 4000 слов.
- Макс 2 фразы, каждая по 8000 слов. Для очень глубокого погружения :)
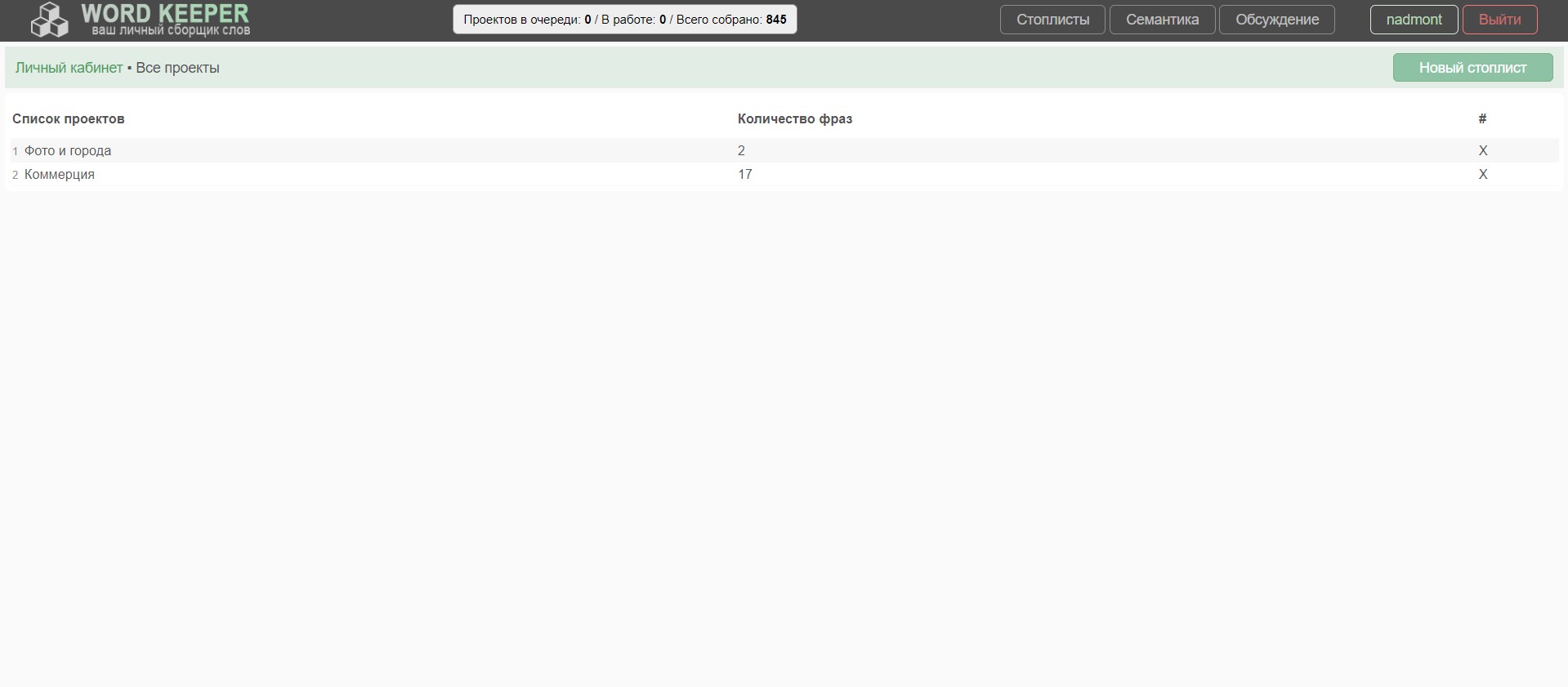
4. Появились Стоплисты. Теперь можно создать стоплист (фразы которые исключить из проекта) и использовать его в различных проектах.
5. Теперь при сборе семантики или частотности можно находится в самом проекте. Правда, любые изменения с ядром сохранены не будут. Поэтому можно только смотреть и ждать конца сбора :)
6. Полностью переписан метод сбора фраз и частотностей. Улучшена многопоточность.
- Скорость сбора фраз: 1000 запросов/ минута
- Скорость сбора частотностей: 4000 запросов/ минута
П.С. Если у вас есть хорошие аккаунты Яндекс почты прошлых годов (без банов яндекса), то вы могли бы помочь мне в улучшении проекта и увеличении скорости сбора.
Спасибо всем, кто поддерживал.




Ginger Dog https://ggds.ru